
Modeling and simulation has become a cornerstone of science and engineering, providing a framework for describing the physical behavior that influences the operation of devices and processes — from the design of smartphones to the control of nuclear power plants. Such behavior may involve electromagnetic fields, fluid flow, heat transfer, and mechanical stresses, to name a few phenomena.
Simulation relies on mathematical descriptions of these effects, formulated as numerical models that give rise to very large systems of equations. The number of unknowns in these systems is directly related to the number of degrees of freedom (DOFs) used in the finite element or boundary element methods. Solving these equations makes it possible to predict the behavior of devices and processes. The predictions can then be used to understand and optimize everything from the placement of a fingerprint sensor in a smartphone to the shape and performance of a turbine blade in a power plant.
This ability to understand, predict, and optimize designs makes it possible to reduce the number of physical prototypes and experiments dramatically, often turning what would require multiple rounds of experimental testing into a largely computational process. However, the large systems of equations that must be solved represent a hurdle for broader adoption, since they often require powerful computers. As a result, most simulation work has traditionally been confined to specialists in R&D departments.
GPU acceleration has the potential to change this. By dramatically reducing solution times, it enables simulation specialists to provide timely modeling insights to teams and departments throughout the organization, driving physics-based decision-making. Specialists can further expand access to GPU-accelerated simulation results by providing nonexpert colleagues with simulation apps they can use to run computations from an intuitive, pared-back user interface. In this post, we will outline how recent advances in GPU-based computation are extending the reach of modeling and simulation.
Why GPU Acceleration Matters for Multiphysics Simulation
Many simulation problems involve not just one physical phenomenon, but several interacting at the same time. Multiphysics simulation captures these interactions — such as heat transfer influencing fluid flow, electromagnetic fields interacting with thermal expansion and mechanical stress, or acoustic waves generated by structural vibration — by coupling them within a single model. These couplings are essential for accurately representing real-world behavior, but they also increase computational demands compared to single-physics analyses.
As multiphysics models grow in size and complexity, involving millions of DOFs, nonlinear couplings, and time-dependent behavior, CPU-based solvers can become a computational bottleneck. These workloads demand enormous amounts of linear algebra operations, particularly during the repeated matrix factorizations that occur in implicit time-stepping and nonlinear solver iterations.
With the latest developments in the COMSOL Multiphysics® software and GPU compute support from NVIDIA®, a new path is emerging. Physics models can be solved more efficiently, and simulation tools can be embedded more deeply into engineering and business processes. In COMSOL Multiphysics® version 6.4, released in November 2025, support has been added for the NVIDIA CUDA® direct sparse solver (NVIDIA cuDSS) for NVIDIA GPUs, which leverages the massively parallel architecture of GPUs to accelerate these computations. GPUs provide thousands of lightweight processing cores and high memory bandwidth, making them well-matched for the demanding numerical workloads common in physics modeling.
When applied using NVIDIA cuDSS, GPU acceleration can make simulations run several times faster. For example, in acoustics transducer simulations — a class of multiphysics analyses important for optimizing miniaturized earbud and smartphone speakers — GPU-enabled solvers have shown substantial speedups compared to CPU-only computations.
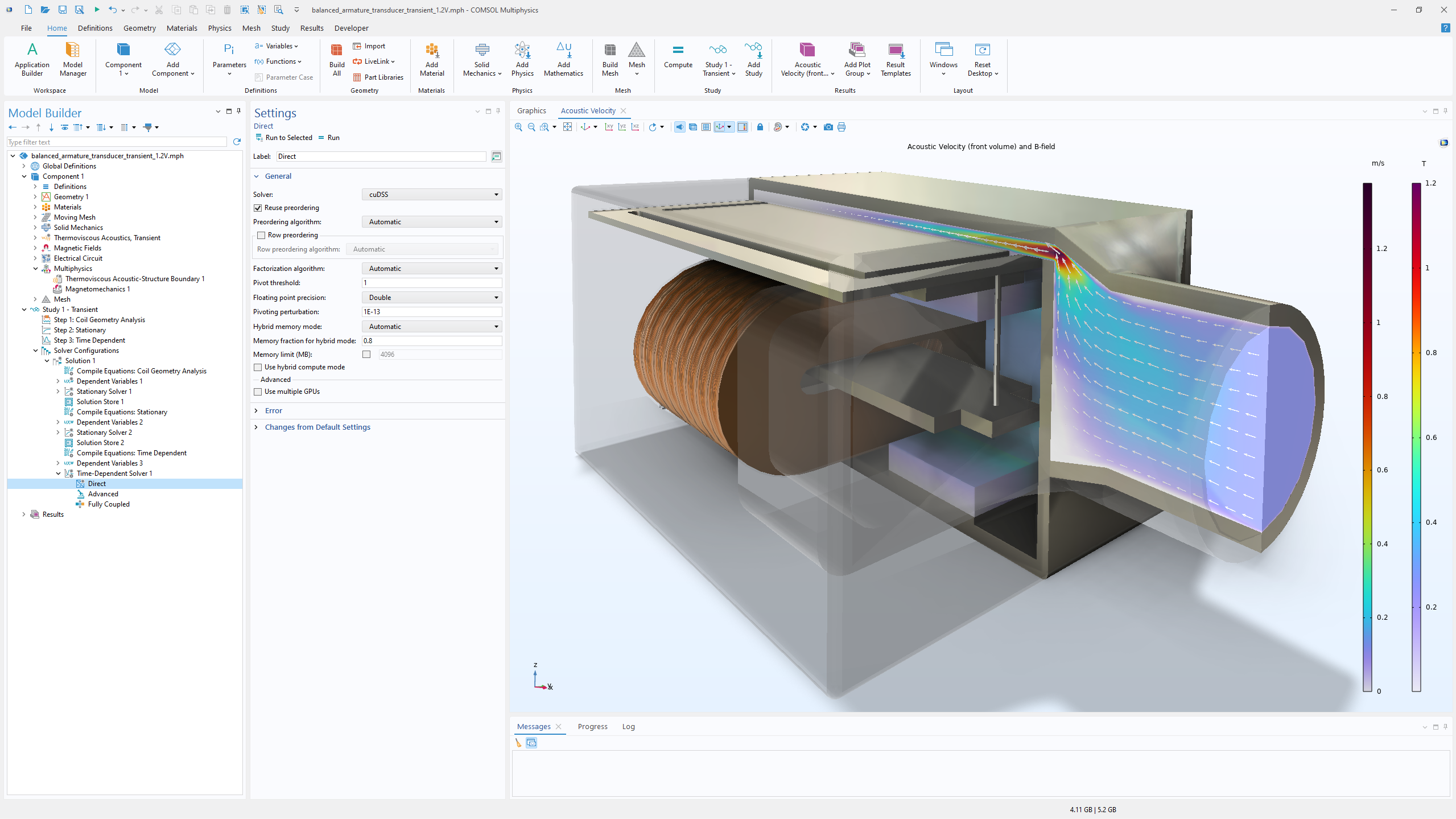 A balanced armature transducer, commonly used in in-ear audio devices, was modeled in the time domain by combining structural analysis, nonlinear magnetics, acoustics, electrical circuits, and moving parts. The multiphysics simulation was solved with the new NVIDIA cuDSS solver on an NVIDIA H100 GPU, achieving an 8× speedup compared to a CPU-based solver running on a workstation equipped with an Intel Core™ i9-10920X processor.
A balanced armature transducer, commonly used in in-ear audio devices, was modeled in the time domain by combining structural analysis, nonlinear magnetics, acoustics, electrical circuits, and moving parts. The multiphysics simulation was solved with the new NVIDIA cuDSS solver on an NVIDIA H100 GPU, achieving an 8× speedup compared to a CPU-based solver running on a workstation equipped with an Intel Core™ i9-10920X processor.
Expanding GPU Coverage in COMSOL Multiphysics®
GPU computing has been steadily integrated into COMSOL Multiphysics® over recent releases, introducing broader capabilities and improved scalability. Version 6.3, released in 2024, introduced GPU acceleration for time-explicit pressure acoustics, implemented through a custom NVIDIA CUDA® based formulation designed for high-frequency and large-domain simulations. The NVIDIA CUDA-X cuBLAS library accelerates this GPU formulation, enhancing performance and efficiency in handling complex computational tasks. The same release also added GPU support for training of deep neural networks (DNN), reducing training time for data-driven surrogate models used in simulation apps and digital twins. With version 6.4, the time-explicit pressure acoustics capability was extended to run on multiple GPUs and GPU clusters.
Version 6.4 further expanded GPU acceleration to general multiphysics simulation through the introduction of NVIDIA cuDSS. The release also added multi-GPU support for models utilizing NVIDIA cuDSS, allowing users to run them with multiple GPUs on one computer. This capability is important not only for performance but also for capacity: Single-GPU simulations are constrained by the memory available on one GPU card. Multi-GPU execution helps overcome these limits, enabling larger models to be solved efficiently.
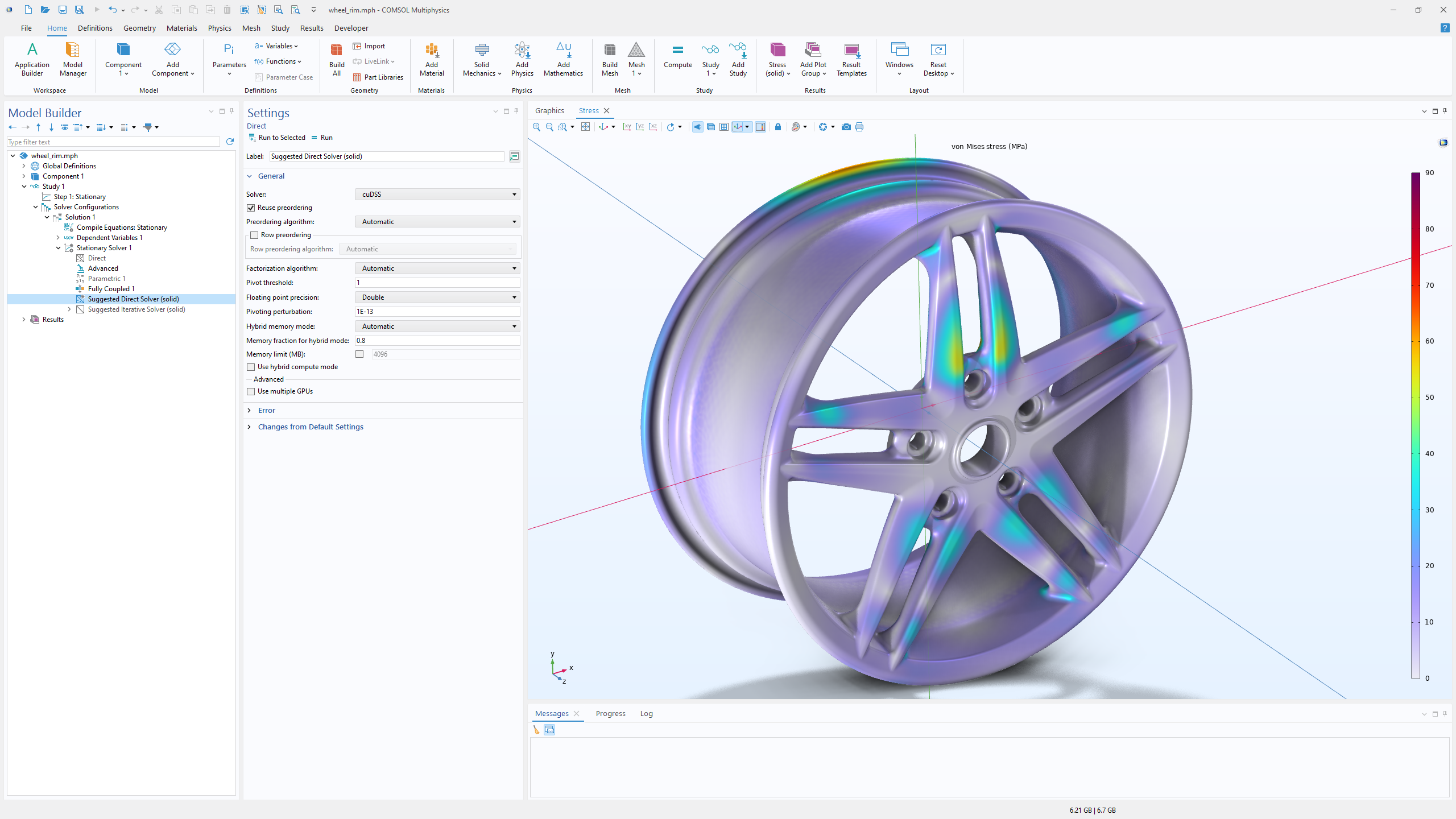 GPU acceleration with NVIDIA cuDSS, new in version 6.4, also benefits conventional structural finite element analyses on standard workstation hardware. In this wheel rim example, the effective stress is visualized, and the GPU-based solve on an NVIDIA RTX™ 5000 Ada Generation workstation GPU achieved a 2× speedup compared with a CPU-based solve on an Intel® W5-2465X processor.
GPU acceleration with NVIDIA cuDSS, new in version 6.4, also benefits conventional structural finite element analyses on standard workstation hardware. In this wheel rim example, the effective stress is visualized, and the GPU-based solve on an NVIDIA RTX™ 5000 Ada Generation workstation GPU achieved a 2× speedup compared with a CPU-based solve on an Intel® W5-2465X processor.
Simulation Apps and Surrogate Models
Recent versions of COMSOL Multiphysics® introduce GPU acceleration into simulation apps: custom, task-specific tools users can create with the Application Builder, the platform’s environment for creating specialized user interfaces on top of physics models. These apps make validated physics models accessible to nonexperts by exposing only key parameters such as geometry, materials, or operating conditions.
Many apps run directly on the underlying high-fidelity model, benefiting from GPU-accelerated solvers to deliver results more quickly. Others can optionally incorporate DNN surrogate models — reduced representations trained on simulation data. Once trained, these DNN surrogates reproduce the behavior of the original model in seconds, and GPU acceleration makes it practical to train them on large datasets and large parameter spaces.
Deploying these apps, which have highly customized and intuitive user interfaces, puts interactive simulation into the hands of teams throughout an organization: Engineers can test design alternatives in real time, manufacturing teams can tune process settings on the shop floor, and operations staff can monitor systems through physics-based digital twins.
For apps that rely on the full model or require verification against it, GPU-accelerated solvers significantly reduce turnaround time for heavy analyses. This speedup also extends to compiled applications built with COMSOL Compiler™, which package the user interface and full solver stack into standalone executables. Compiled apps benefit from GPU acceleration just like desktop COMSOL® installations, allowing high-performance simulation tools to be distributed without paid-for software licenses.
Together, simulation apps, surrogate models, GPU-accelerated solvers, and compiled executables provide a scalable way to extend physics-based analysis to a wider range of users. A single validated model can evolve into a family of deployable tools, from near-instant surrogate predictors to GPU-accelerated full-fidelity solvers, all built on the same multiphysics foundation.
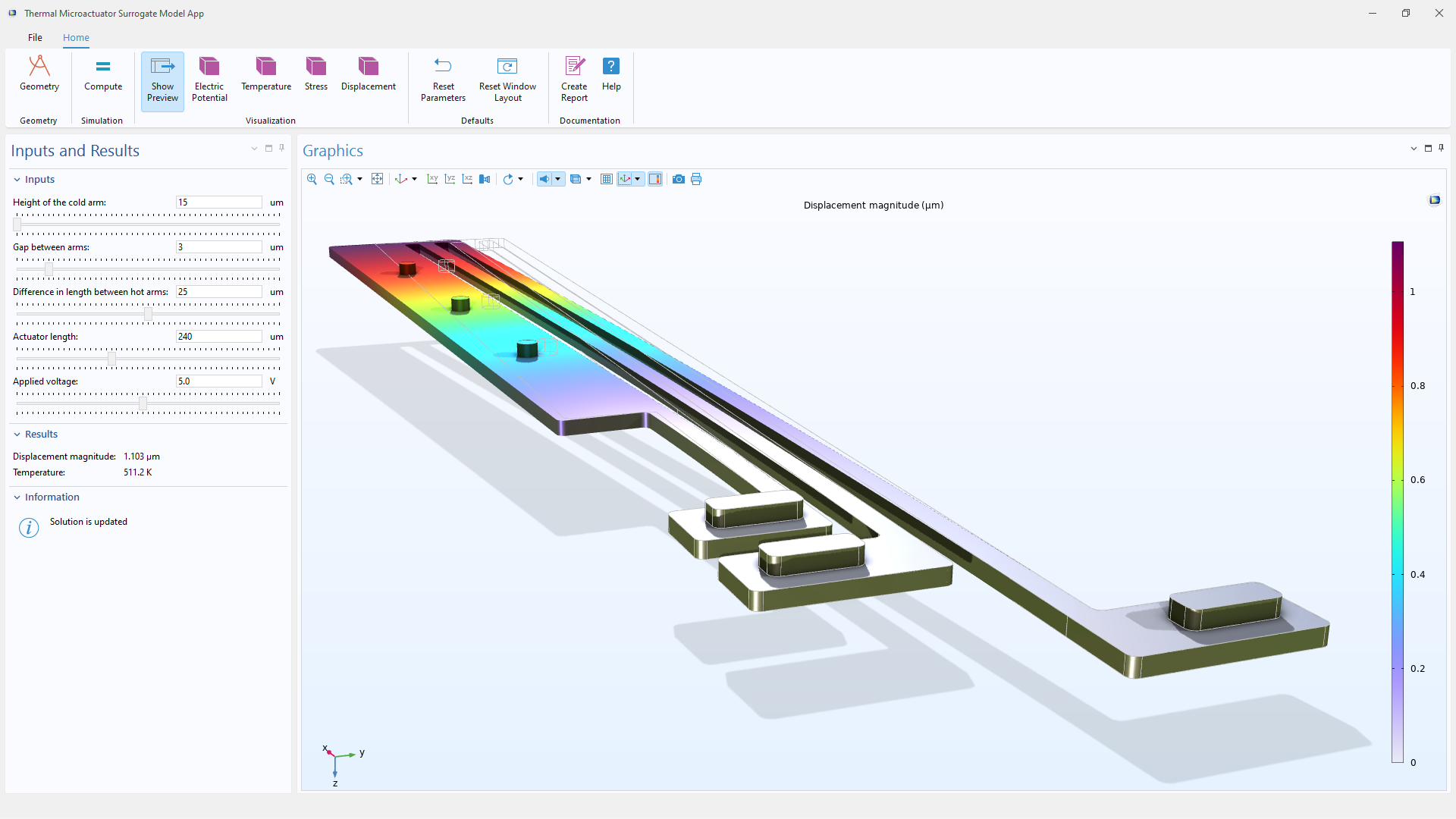 A simulation app for a MEMS thermal actuator powered by a DNN surrogate model, enabling extremely fast model evaluation of quantities such as temperature, displacement, voltage, and stress. The surrogate model was trained using GPU acceleration on a standard workstation.
A simulation app for a MEMS thermal actuator powered by a DNN surrogate model, enabling extremely fast model evaluation of quantities such as temperature, displacement, voltage, and stress. The surrogate model was trained using GPU acceleration on a standard workstation.
The NVIDIA CUDA® Direct Sparse Solver (NVIDIA cuDSS)
At the core of the latest GPU acceleration capabilities in COMSOL Multiphysics® lies the NVIDIA CUDA® direct sparse solver (NVIDIA cuDSS) for NVIDIA GPUs. This solver is designed to accelerate one of the most computationally demanding steps in many multiphysics workflows: the repeated solution of large, sparse linear equation systems that arise in implicit time stepping, nonlinear analyses, parametric sweeps, and eigenfrequency studies.
Sparse direct solvers typically rely on matrix factorizations, specifically highly optimized, robust versions of Gaussian elimination. These operations demand both high floating-point throughput and rapid memory access — areas where GPUs excel. The massive memory bandwidth available on GPUs allows NVIDIA cuDSS to move large sparse matrices through memory much faster than CPU-based solvers. This bandwidth advantage, combined with thousands of parallel compute cores, significantly reduces wall-clock time for large-scale computational engineering models.
NVIDIA cuDSS supports both single-precision and double-precision arithmetic. Whether single precision is suitable depends on details of the model such as mesh quality, boundary conditions, material properties, and load definitions, which all influence the conditioning of the linear systems being solved. Because these factors are difficult to assess in advance, users may need to test whether single precision produces stable and accurate results for their specific simulation.
When single precision is viable, the performance gains can be significant. Single precision cuts memory usage in half and increases floating-point throughput, which can yield substantial speedups, especially for compute-bound problems or when running on lower-cost GPUs that offer higher single-precision than double-precision performance. For memory-bound workloads, the improvement is typically closer to a factor of two due to bandwidth limits. Double precision remains the appropriate choice for simulations that demand higher numerical accuracy and is the default option when using NVIDIA cuDSS in COMSOL Multiphysics®.
Because NVIDIA cuDSS integrates seamlessly into the solver framework in COMSOL Multiphysics®, it can be applied to a wide range of physics simulations, from linear analyses to fully coupled nonlinear multiphysics models. It can be used wherever direct solvers are used today, including as part of a preconditioner within iterative solver methods.
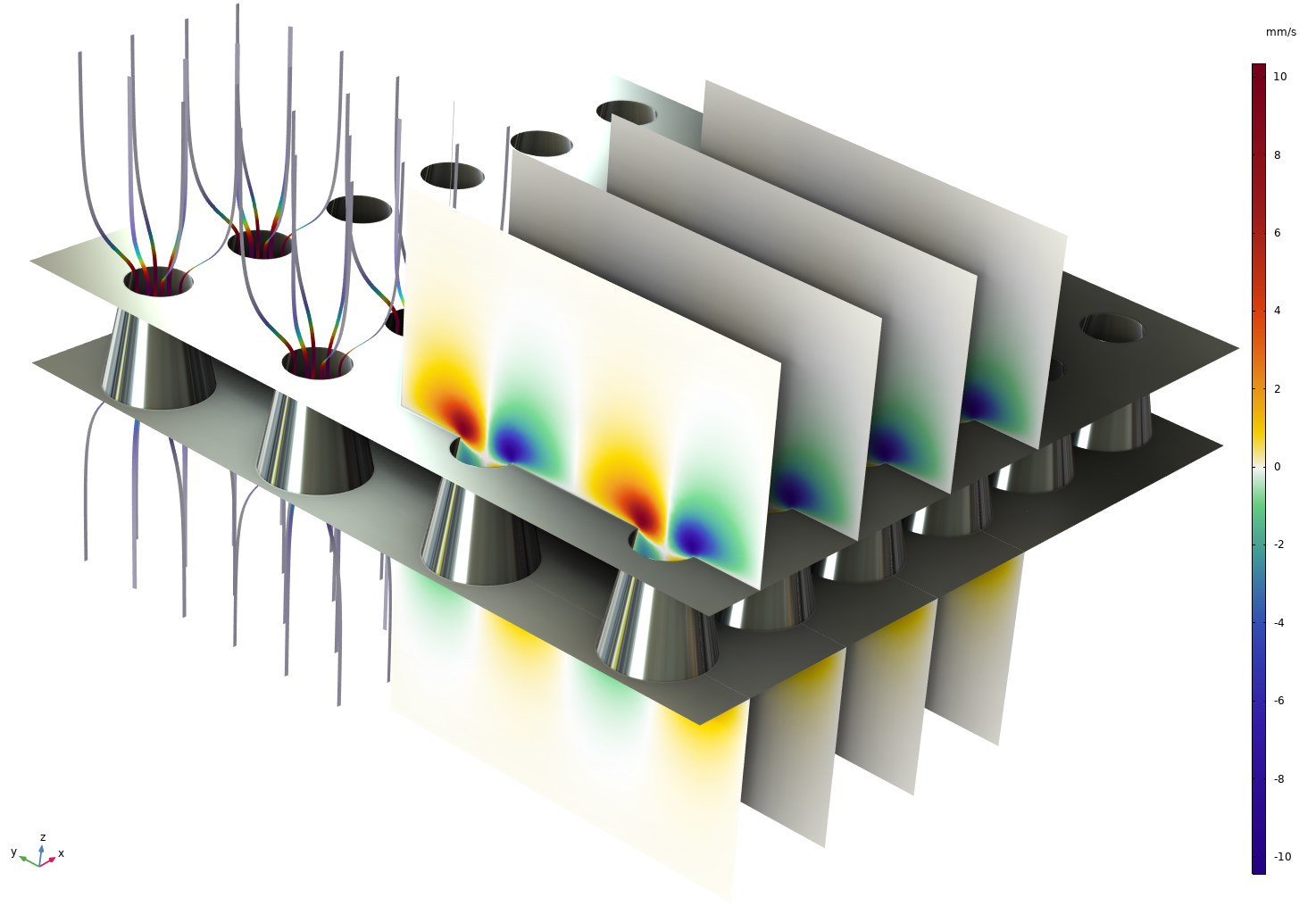
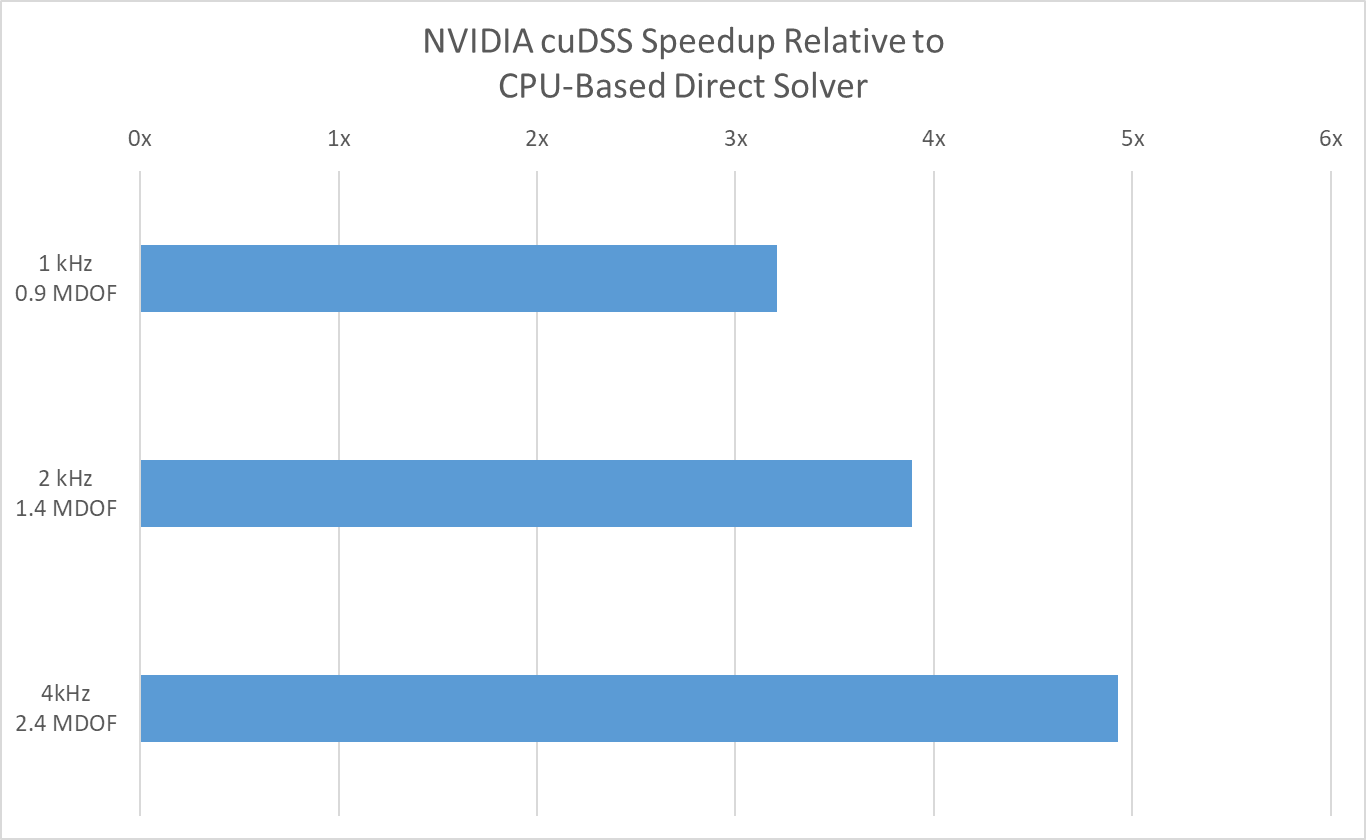
Acoustic transfer-impedance multiphysics model of a perforated plate used in mufflers and acoustic liners, solved with NVIDIA cuDSS on four NVIDIA H100 GPUs. The image shows the acoustic particle velocity. Benchmarking at three model sizes (0.9—2.4 million DOFs) shows a nearly 5× speedup over a CPU-based direct solver on a dual Intel® Xeon® Platinum 8260 system.
Making GPU-Accelerated Simulation More Widely Accessible
With GPU-accelerated NVIDIA cuDSS, COMSOL Multiphysics® can solve large, sparse systems much faster, turning what were once overnight computations into simulations that finish within hours. The same acceleration benefits smaller and medium-sized models that must be run thousands of times in parametric sweeps, such as when generating training data for neural network surrogate models. In combination with simulation apps, these capabilities help take a full physics model and turn it into a set of widely applicable tools, moving advanced multiphysics simulation from isolated expert workflows to everyday engineering practice.
Further Reading
Learn about the key factors to consider when selecting a GPU for use in COMSOL Multiphysics® in the Learning Center article, “GPU Selection Guidelines for COMSOL Computing”, accessible via the button below.


Comments (0)