
High-Performance Computing (HPC)
The Basics of HPC
High-performance computing, otherwise known as HPC, refers to the use of aggregated computing power for handling compute- and data-intensive tasks – including simulation, modeling, and rendering – that standard workstations are unable to address. Typically, the problems under consideration cannot be solved on a commodity computer within a reasonable amount of time (too many operations are required) or the execution is impossible, due to limited available resources (too much data is required). HPC is the approach to overcome these limitations by using specialized or high-end hardware or by accumulating computational power from several units. The corresponding distribution of data and operations across several units requires the concept of parallelization.
When it comes to hardware setups, there are two types that are commonly used:
- Shared memory machines
- Distributed memory clusters
In shared memory machines, random-access memory (RAM) can be accessed by all of the processing units. Meanwhile, in distributed memory clusters, the memory is inaccessible between different processing units, or nodes. When using a distributed memory setup, there must be a network interconnect to send messages between the processing units (or to use other communication mechanisms), since they do not have access to the same memory space. Modern HPC systems are often a hybrid implementation of both concepts, as some units share a common memory space and some do not.
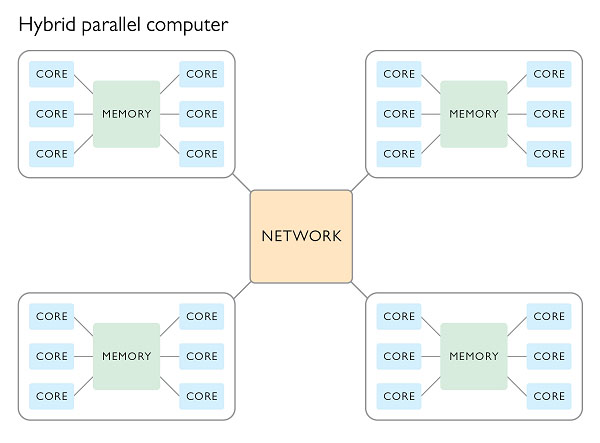
- A diagram showing the dynamics of hybrid parallel computing, an important element in HPC.
Reasons to Use HPC
HPC is primarily used for two reasons. First, thanks to the increased number of central processing units (CPUs) and nodes, more computational power is available. Greater computational power enables specific models to be computed faster, since more operations can be performed per time unit. This is known as the speedup.
The speedup is defined as the ratio between the execution time on the parallel system and the execution time on the serial system.
The upper limit of the speedup depends on how well the model can be parallelized. Consider, for example, a fixed-size computation where 50% of the code is able to be parallelized. In this case, there is a theoretical maximum speedup of 2. If the code can be parallelized to 95%, it is possible to reach a theoretical maximum speedup of 20. For a fully parallelized code, there is no theoretical maximum limit when adding more computational units to a system. Amdahl’s law explains such a phenomenon.
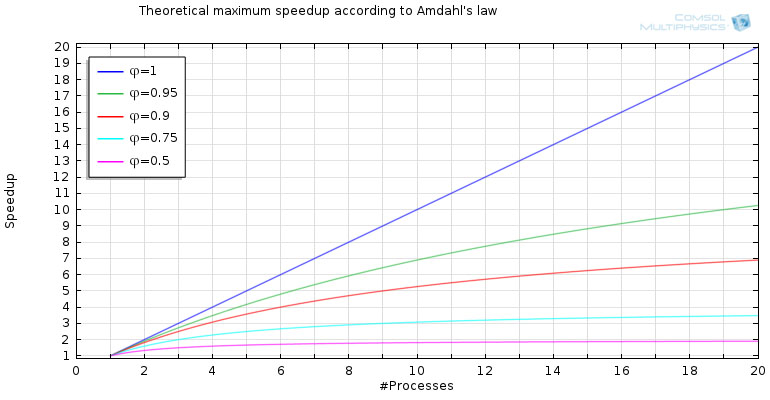
- Plot depicting the theoretical maximum speedup according to Amdahl's law.
Second, in the case of a cluster, the amount of memory available normally increases in a linear fashion with the inclusion of additional nodes. As such, larger and larger models can be computed as the number of units grows. This is referred to as the scaled speedup. Applying such an approach makes it possible to, in some sense, “cheat” the limitations posed by Amdahl’s law, which considers a fixed-size problem. Doubling the amount of computational power and memory allows for a task that is twice as large as the base task to be computed within the same stretch of time. Gustafson-Barsis' law explains this phenomenon.
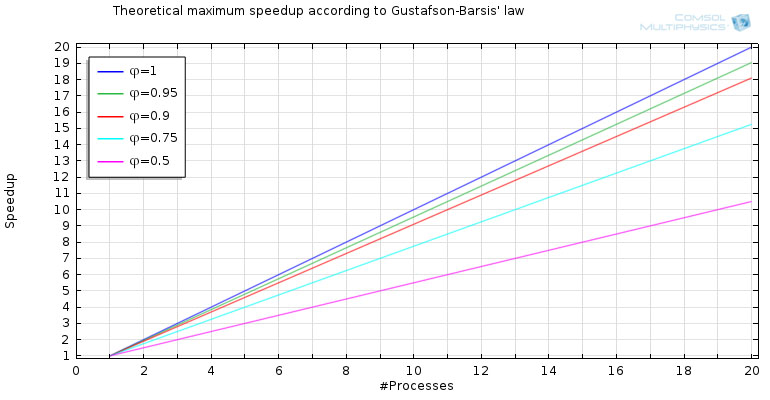
- A plot illustrating the theoretical maximum speedup according to Gustafson-Barsis' law.
Parallelization
Different types of modeling problems are parallel to different degrees. Take a parametric sweep, for instance, that involves computing a similar model with several independent geometries, boundary conditions, or material properties that can be parallelized almost perfectly. This is accomplished by giving one model setup to each computational unit. These types of simulations are so fit for parallelization that they are usually called “embarrassingly parallel problems”.
Embarrassingly parallel problems are very insensitive to the speed and latency of the network in the cluster. (In other cases, this may potentially cause a slowdown, as the network is not fast enough to handle communication effectively.) It is, therefore, possible to connect commodity hardware to speed up the computations of such problems (i.e., to build a Beowulf cluster ).

- A Beowulf cluster.
Many types of problems can be divided into smaller parts, or subproblems. Smaller parts can be built, for example, by decomposition of data (data parallelism) or decomposition of tasks (task parallelism). The degree of coupling between these subproblems influences their degree of parallelization.
An example of an almost fully decoupled problem would be an embarrassingly parallel one, such as the parametric sweep discussed above. An example of a problem that is fully coupled would be an iterative process , where the computation of
must be done in a strictly serial fashion.
When subproblems are coupled, they cannot be handled independently, since intermediate results of one subproblem may depend on other subproblems. One needs to take care of these dependencies by information exchange (that encompasses additional work compared to the original serial problem). Either shared memory or the interconnection network can be used for communication and synchronization between the different computational units. Depending on if a computation is running in a shared memory environment or a distributed memory environment, various factors have an impact on parallelization and possible speedups.
When running distributed memory simulations over several nodes, the computational units must use the network to communicate. Here, network latency and bandwidth further influence the speed of communication. Most HPC clusters are therefore equipped with high-bandwidth/low-latency networks, delivering data quickly between the cluster's different nodes.
Published: March 7, 2016Last modified: February 21, 2017