
Have you ever wondered if the topology of your model geometry (in other words, the decomposition of the geometry into geometric entities like domains, boundaries, edges, and vertices) somehow influences how the mesh generation in the COMSOL Multiphysics® software makes use of your computational resources? If so, then this blog post will be of interest to you…
Parallelized Meshing in COMSOL Multiphysics®
The following operations make use of shared memory parallelism:
- Free Tetrahedral
- Free Triangular
- Free Quad
- Mapped
- Boundary Layers
- Swept
The Free Tetrahedral operation parallelizes across domains and faces. This means that when the operation generates the tetrahedra on a geometry with four domains, it can utilize a maximum of four cores, while the same operation can only use one core if there is one domain in the geometry — regardless of the number of cores available. Similarly, the Free Triangular, Free Quad, and Mapped operations are parallelized across domains in 2D and faces in 3D.
The Boundary Layers operation is partly parallelized. Unlike the other operations, this mesh operation is parallelized within each domain.
Lastly, the meshing of linking faces (done with the Mapped operation) is part of the Swept operation, which is parallelized.
Note that the mesh is built, one operation at a time, from the top down in the sequence of mesh operations. The parallelization is therefore done per operation, one at a time.
A Benchmark Performance Test
How much does parallelized meshing speed up the meshing time in an actual modeling scenario? Let’s take a 6×1×1-m block and mesh it on a regular desktop computer with 6 cores. One Free Tetrahedral operation is added under Mesh. The following mesh element size parameters are used throughout the test:
- Maximum element size:
0.02 m - Minimum element size:
0.01 m
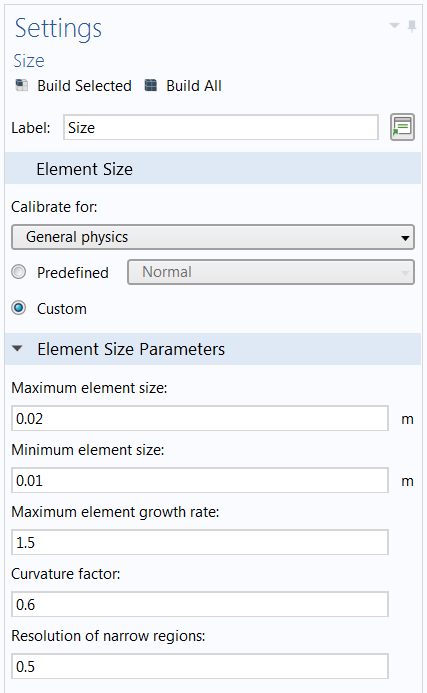
Mesh Size settings used in the benchmark test.
These settings give a very fine mesh, which results in roughly 13 million tetrahedral elements.
We set up three test cases in which the model has:
- One domain
- Six domains, partitioning the block into six equally sized domains
- Six domains, restricting the software to run on only one core
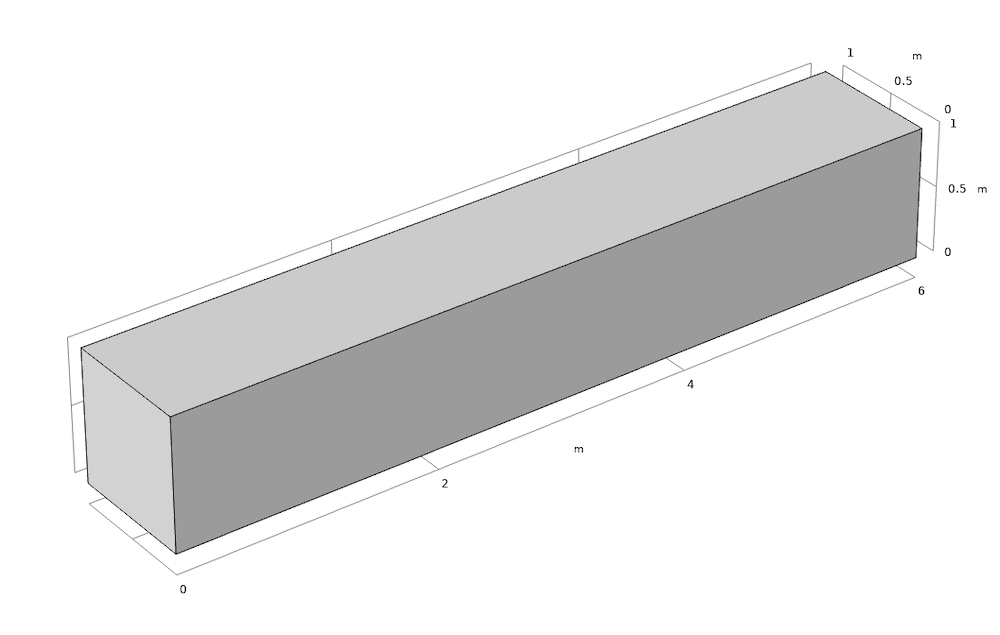
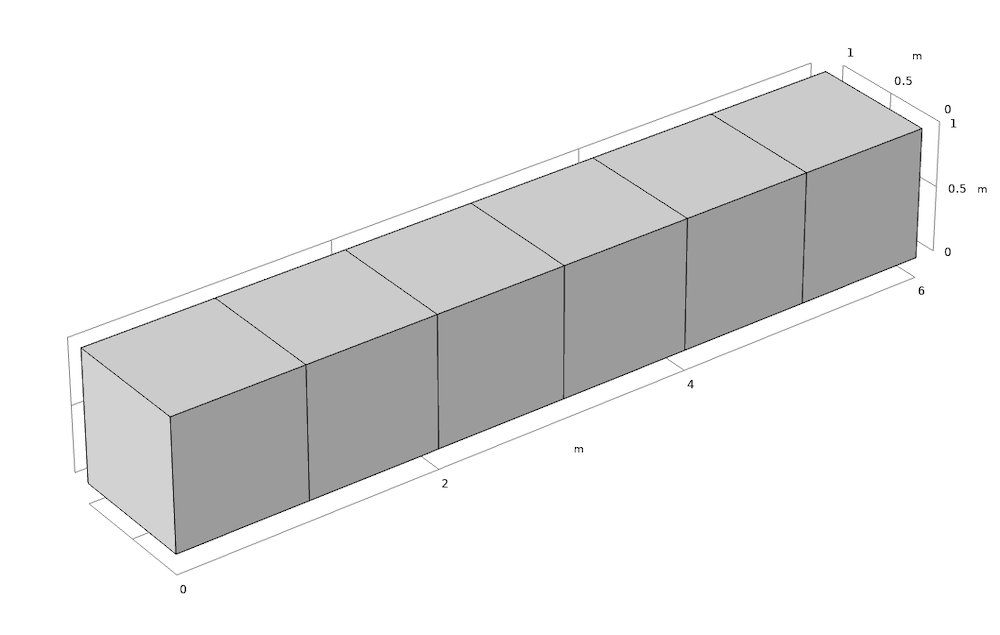
Left: A 6×1×1-m block with 1 domain (case 1). Right: A geometry with the same outer size as case 1, but divided into 6 domains of size 1×1×1 m (cases 2 and 3).
To restrict the software to run on only one core, you can add the option -np 1 to the start command. It is also possible to do this on the Multicore and Cluster Computing page in the Preferences dialog box.
Benchmark Results and Discussion
The results from the 3 tests are gathered in the table below. The meshing in cases 1 and 3 will run on only 1 core and take about the same time to mesh. The geometry with 6 domains (cases 2 and 3) has more boundaries and therefore results in more triangle elements, which also means that this geometry requires slightly more meshing work. In case 2, where the mesh algorithm uses all 6 cores, meshing is reduced to less than 25% of the time it takes when using only one core.
| Case | Domains | Time | Triangle Elements | Tetrahedral Elements |
|---|---|---|---|---|
| 1 | 1 | 136 s | 1.51e3 | 13.0e6 |
| 2 | 6 | 31 s | 1.81e3 | 13.0e6 |
| 3 (1 core) | 6 | 147 s | 1.81e3 | 13.0e6 |
Results from a benchmark test run on a six-core desktop computer. The test shows a significant speedup from one core (first and third rows in the table) to all six cores (second row in the table).
You might be wondering if you should partition your geometry into as many domains as you have cores, assuming you have fewer domains to begin with. The answer? Not necessarily…
Partitioning a domain leads to more boundaries. This sets more constraints on the mesh, which, in turn, might give a more complex situation to mesh. The increase in boundaries will take a longer time to mesh, which is most clearly seen by comparing the times and number of triangle elements in cases 1 and 3. You should also consider that partitioning a domain can lead to narrow regions that require a finer mesh size. Note that the situation in this benchmark is idealized; there are six equal domains on six cores. In a real case, it is more likely that some domains are more complicated and dominate meshing time, leading to less speedup.
Partitioning Domains with Boundary Layers
The Boundary Layers operation moves points in parallel when inserting boundary layer elements and can do so even when operating on a single domain. Therefore, partitioning domains will not improve performance, but rather the opposite, since the extra partitioning faces need more processing.
How Many Mesh Operations Can I Use Without Losing Performance?
Let’s use case 2 in the benchmark example above (six domains meshed on at maximum six cores). The parallelization is done per mesh operation so if we now add another Free Tetrahedral operation and mesh three domains in each operation, a maximum of three cores can be used. In general, it is recommended to use as few mesh operations (of the same type) as possible. This will not only make it possible to parallelize as much as possible, but it will also allow for a good optimization of the quality of the mesh. To set different size settings on different domains/boundaries, use several global or local size attributes and only one Free Tetrahedral operation. The Using Meshing Sequences tutorial discusses the details about setting global and local size attributes.
Concluding Thoughts on Meshing Run in Parallel
In this blog post, we have discussed the ways in which the meshing algorithm in COMSOL Multiphysics is parallelized. The results from a simple benchmark test show that meshing run in parallel can significantly speed up the algorithm by distributing the meshing of domains on more cores.
Suggested Reading
For more information about the Free Tetrahedral operation, and possible ways to modify a geometry, check out these resources:


Comments (11)
Said Bouta
May 3, 2019Hi
On which base taking values of the size min and max, if for example I have a cube of dimension L = 200mm, and inside this cube, I have a sphere of radius r = 10mm
also, how to choose the growth rate, curvature factor and resolution of narrow regions
Khalid Hussain
May 3, 2019can any body help me to resolve this problem
after preparing the model in comsol we apply the specific voltage then how we come to know that electric breakdown or discharge take place or electric breakdown……
and how we come to know that at which level of voltage electric breakdown take place
Hanna Gothäll
May 6, 2019 COMSOL EmployeeHi Said,
In general, it is often OK to use the Predefined Mesh Sizes available. To learn more about how to set up a manual Mesh sequence with manually specified mesh size parameters, please refer to the following tutorials:
https://www.comsol.com/model/using-meshing-sequences-13869
https://www.comsol.com/model/free-tetrahedral-meshing-of-a-piston-geometry-14439
For more specific questions about your particular application, send your model MPH file to support@comsol.com.
Hanna Gothäll
May 6, 2019 COMSOL EmployeeDear Khalid,
This sounds like a type of question which is best addressed by COMSOL’s Support team. Please send your model MPH file to support@comsol.com or use the following contact form:
https://www.comsol.com/support/case/
Oscar Diaz
May 6, 2019Hej Hanna,
Very interesting test, my everyday problem is meshing. Few questions:
1. On your multicore test, did you use a different Mesh node / free tets node for each domain?
2. In general, is there any difference in the amount of mesh/tets nodes you include to mesh your geometry?
3. Do the meshing task follow any specific order/hierarchy in the model builder tree (e.g. the 1st line and then the 2nd)?
Tack!
Hanna Gothäll
May 7, 2019 COMSOL EmployeeHej Oscar,
I’m glad that you found the blog post interesting. Here are my answers to your questions:
1. I used only one Free Tetrahedral operation for all three cases, it was just the number of domains that changed between the cases. The text will be updated to reflect this.
2. Yes, the situation changes depending on how many feature nodes you add to your mesh sequence. The parallelization can only be done per mesh operation so if I had added three domains in two different Free Tetrahedral feature nodes, only three cores can be used. In general, it is recommended to use as few mesh operations as possible. To set different size settings on different domains, use several global or local size attributes and only one Free Tetrahedral node. Please refer to the first meshing tutorial linked in the comment above (Using meshing sequences) for more details about this. The text above will be updated to include this information.
3. The meshing algorithm does, in general, start from the top and go all the way down, working with one operation at a time. The first meshing operation doesn’t know of any subsequent mesh operations or global size attributes, it only knows about the preceding ones and local size attributes.
Yannick Dufil
July 22, 2020Hello,
How does comsol manage the parallelization of calculations with a machine containing several CPU (especially for meshing)? Would it be useful to divide my totally symetrical device into as many domain as the sum of the cores in my CUPs or is it a more complexe calculation?
Hanna Gothäll
August 10, 2020 COMSOL EmployeeHello Yannick,
The parallelization explained in the blog article includes the case of a computer containing several CPUs. Whether or not it will be more efficient to divide the domain into several smaller domains is something you will need to try out for your particular geometry and meshing sequence. For more specific advice, send the MPH file to support@comsol.com to get help from our support team.
Sam Parler
December 15, 2020My 8-year-old, 2-cpu (Xeon E5-2687W) with total of 32 cores at 3.10 GHz, 16 threads, 8 ECC ram slots with equal 16 GB sticks in each slot for this 1x1x6 domain with the 0.01m min and 0.02m max element sizes in Free Tetrahedral mesh builds in the following times:
Single domain: 200 seconds
4 domains: 65 s.
8 domains: 41 s.
16 domains: 32 s.
32 domains: 32 s.
Hanna Gothäll
December 17, 2020 COMSOL EmployeeHi Sam,
I’m glad you found the topic of the blog post interesting. Are you sure about the number of cores? That type of machine typically has 16 cores, not 32, making the times listed in the table correct.
Sam Parler
December 17, 2020I believe you are right about that. I have a 2-cpu machine and Intel lists each CPU as having 8 cores and 16 threads.
What confused me was that Windows’ “Computer Management” app under Processors displays a list of 32 processors. I am wondering if that is from the threads or what.